Understanding Flash Attention: Making Transformers Fast
Sun Jun 21 2026
Flash Attention from First Principles. Most people understand Self-Attention, but don’t know exactly why it is so incredibly slow for long documents.
To understand how modern models can process millions of tokens at once, we need to understand Flash Attention.
It essentially solved the quadratic memory bottleneck.
But before we get into the solution, we must understand the core problem.
Step 1: The Matrix Gets Too Big
When a model processes text, it compares every single word to every other word using the Self-Attention mechanism.
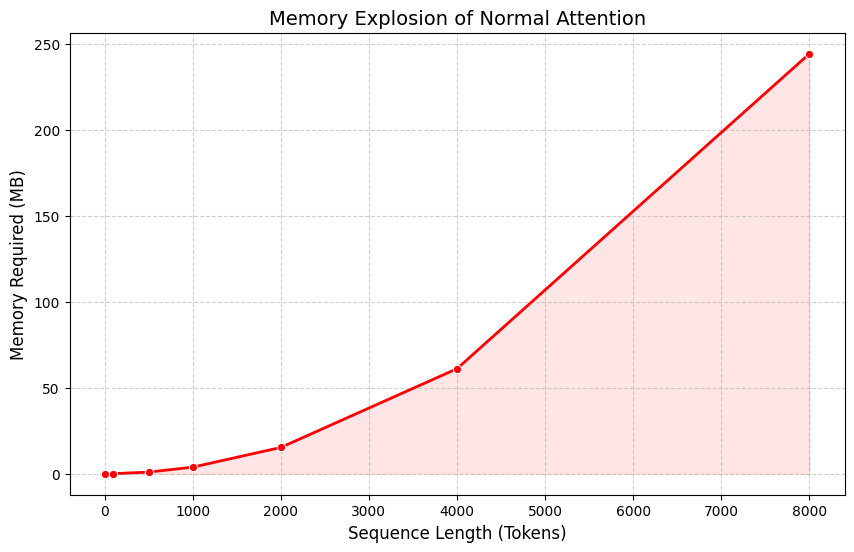
This creates a massive Attention Matrix. Look at how the math problem scales:
| Number of Words | Math Problem Size (Attention Matrix) |
|---|---|
| 1,000 words | 1,000,000 numbers |
| 2,000 words | 4,000,000 numbers |
| 4,000 words | 16,000,000 numbers |
| 8,000 words | 64,000,000 numbers |
Notice: Every time you double the words, the memory you need multiplies by 4. This gets out of hand very fast.
The Math Term: O(N²) (Quadratic Scaling)
The Rule:
If your sequence gets longer, the Attention Matrix explodes. You need an insane amount of memory.
Here is the craziest part: Why are we forcing the GPU to create a gigantic 64-million-number matrix, if we are just going to throw it away a second later?
Step 2: The FlashAttention Question
Standard Attention creates 64,000,000 numbers, saves them to the GPU’s slow main memory (HBM), reads them back to do the Softmax math, and then deletes them.
Moving all those numbers back and forth is the real reason Transformers are slow. FlashAttention asks: Can we skip the slow memory completely?
Step 3: The Old Matrix vs. The Chunked Matrix
To solve this, we can introduce Tiling (Chunking).
Standard Attention:
Builds the massive matrix all at once in the slow memory.
Tiled Attention:
Does the math in pieces. It does a small piece, then another small piece, and so on. All of this fits inside the ultra-fast memory (SRAM).
The Important Rule
We are not skipping any steps.
We are still comparing every single word against every other word. We are just doing it in small, manageable batches instead of one giant gulp. The final mathematical answer will be exactly the same.
Why does chunking matter so much?
The GPU’s fast memory (SRAM) is incredibly fast, but very small. By doing the math in chunks, we keep all the work inside the fast memory. We avoid the brutal speed limits of the massive, slow main memory.
Step 4: But Wait… Tiling Breaks Softmax
We are going to prove why we can’t just easily chop the math into small pieces. Normal Softmax is not the same as Tiled Softmax.
The Golden Rule of Softmax
Imagine we have raw scores for one word looking at four other words: [2, 5, 1, 8]
Normal Attention:
The Softmax function looks at all four numbers at the exact same time. It figures out the percentages based on the whole group. The percentages will always add up to exactly 100% (or 1.0).
The Chunking Mistake
Suppose we decide to be clever and chop the scores into smaller chunks (tiles) so they fit in the GPU’s super-fast memory.
- Tile 1:
[2, 5] - Tile 2:
[1, 8]
It feels logical to do Softmax on Tile 1, then Softmax on Tile 2, and add them together. But watch what happens.
The 200% Bug
Because we chopped the keys, the Softmax in each chunk doesn’t know about the other chunk. It forces each tiny chunk to equal 100% all by itself.
The Correct Answer:
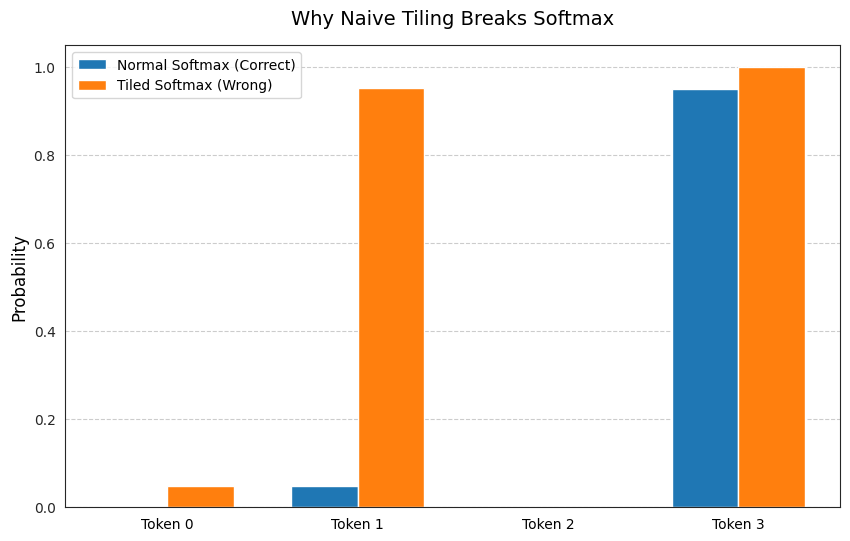
If we do Softmax([2, 5, 1, 8]) all at once, we get [0.002, 0.047, 0.001, 0.950].
If you add those up, you get 1.0 (100%). Everything is perfect.
How It Breaks Chunk by Chunk:
Tile 1:
We ask Softmax to process [2, 5]. It thinks 5 is the biggest number ever, so it gives it 95%. The result is [0.047, 0.953]. (Adds up to 100%).
Tile 2:
We ask Softmax to process [1, 8]. It gives 8 almost everything. The result is [0.001, 0.999]. (Adds up to 100%).
The Trap:
If we stick those answers back together: [0.047, 0.953, 0.001, 0.999].
Add them up, and the sum is 2.0!
We just distributed 200% attention. The math is completely broken. Because Tile 1 couldn’t see the massive 8 in Tile 2, it gave the 5 way too much importance.
Step 5: The Magic Trick - Online Softmax
We just saw that chopping Softmax into chunks causes a massive bug. So how do we fix it?
The FlashAttention Goal:
How can we process the numbers in small, fast chunks, but still get the exact same math as if we looked at all the numbers at once?
Instead of needing to see every single number at the same time, we use a clever math trick called Online Softmax. We only need to remember two numbers as we process the chunks:
- The Maximum: What is the biggest score we have seen so far?
- The Sum: What is the running total of our calculations?
By keeping track of just these two tiny numbers, we barely use any memory.
Why is it called “Flash” Attention?
Because the “Maximum” number constantly updates (or “flashes”) as we process new chunks. When we find a new biggest number, the algorithm uses a smart formula to reach back and instantly fix the percentages of the old chunks.
We never have to save the big matrix!
Step 6: The Flash Attention Forward Pass
The Old Way (Standard Attention)
The standard way is terrible because it relies on the slow main memory (HBM):
- Move Q and K from slow memory to fast memory.
- Do the math. Write the giant result back to slow memory.
- Read the giant result from slow memory to do Softmax. Write it back.
- Read it again to multiply by V. Write the final answer.
All we are doing is moving data back and forth. It is slow.
The New Way (FlashAttention)
FlashAttention does everything in one smooth motion using the super-fast memory (SRAM):
- Load a Chunk: Bring a small piece of Q, K, and V into fast memory.
- Do the Math: Multiply them together.
- Update the Trackers: Update the Running Maximum and Running Sum.
- Update the Output: Keep building the final answer.
- Throw the Chunk Away: Clear the fast memory and load the next piece.
We never write the giant middle step to the slow memory. This is why it is so fast!
Step 7: The Benchmark Results
When we benchmark Flash Attention against standard attention, the results are massive. The larger the sequence length, the more standard attention slows down and runs out of memory, while Flash Attention maintains steady performance.
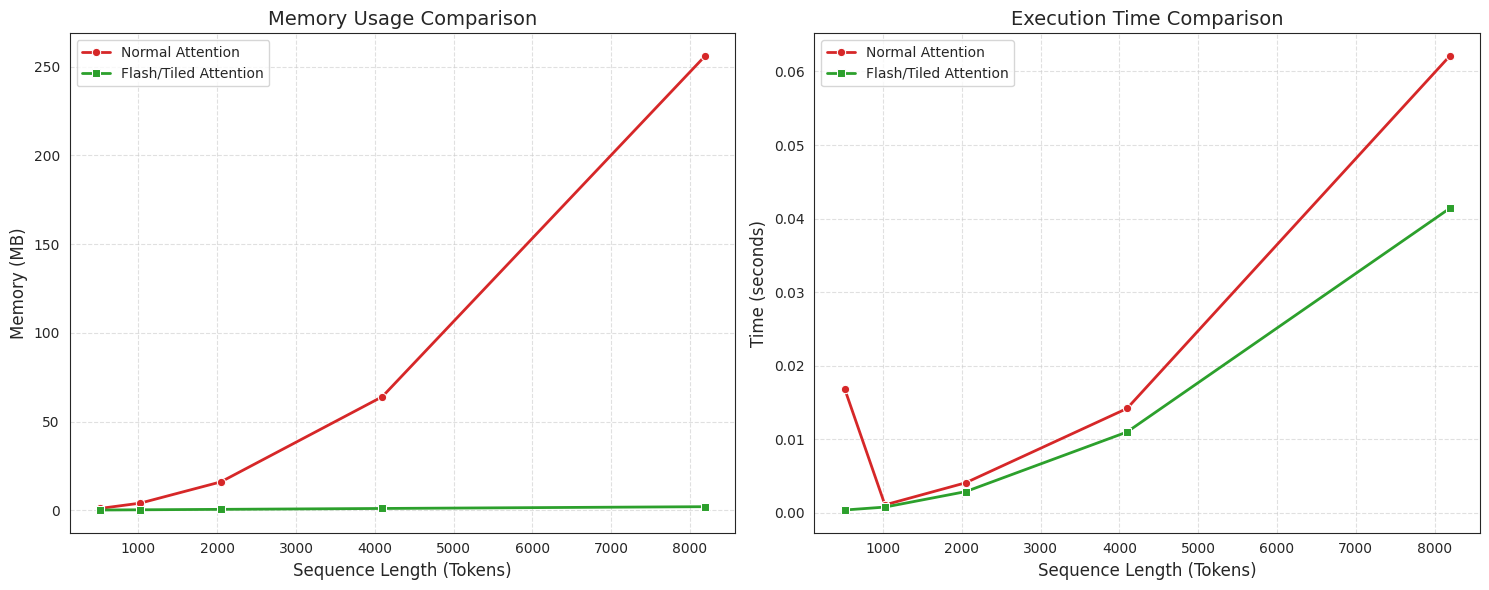
FlashAttention was the turning point that allowed us to move from 4K context windows to 128K, 1M, and beyond.
Comment down your thoughts below, if you found it helpful !
References
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-AwarenessBest,
Ankit