Understanding QTIP & QUIP Quantization: Shaping Error to Save Memory
Sun Jun 21 2026
QTIP and QUIP Quantization from First Principles. Most people understand basic INT8 quantization, but don’t know exactly why lower bit-widths like INT4 completely destroy model quality, and how we fix it.
To understand how we can run massive models on consumer hardware, we need to understand the evolution of quantization up to QTIP.
It essentially solved the sub-8-bit precision loss bottleneck.
But before we get into the solution, we must understand the core problem.
Step 1: Why INT8 Is Not Enough
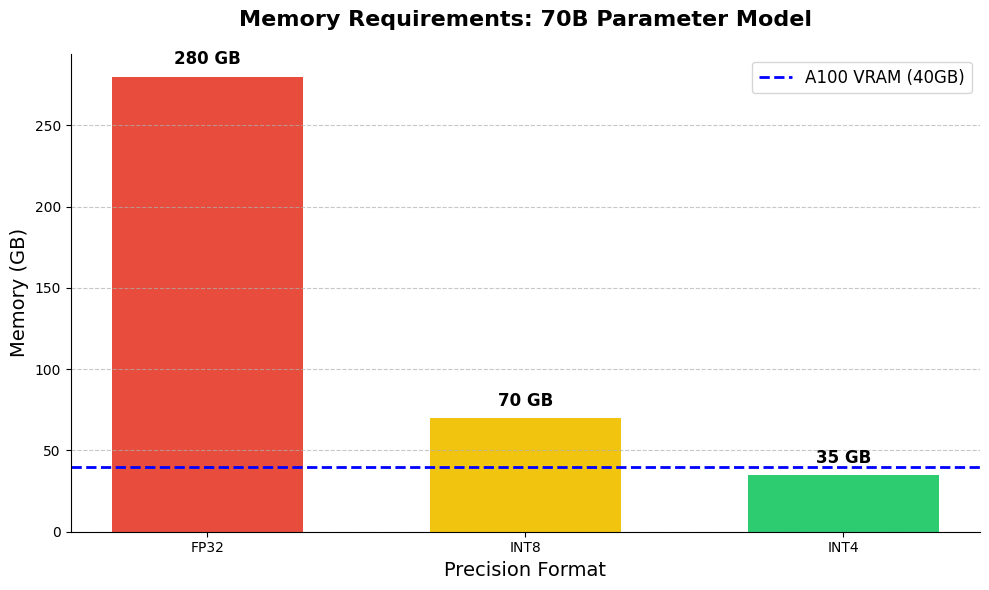
When running a massive Transformer model, memory is the biggest bottleneck. Storing a 70 Billion parameter model in 32-bit floating point (FP32) requires nearly 280 GB of VRAM.
By dropping down to INT8, we can cut this requirement by 75%. But for edge devices or consumer GPUs, even INT8 is not small enough. The holy grail is sub-8-bit quantization (like INT4 or INT2), which drastically reduces the memory footprint.
Step 2: Why INT4 Fails
If INT8 works so well, why can’t we just use INT4 everywhere?
The answer lies in Bucket Resolution. INT8 gives us 256 distinct values (buckets) to represent our weights. INT4 gives us only 16 buckets.
When you force a complex, highly-tuned distribution of weights into just 16 buckets, you experience severe Information Collapse. The model loses the subtle nuances that make it smart.
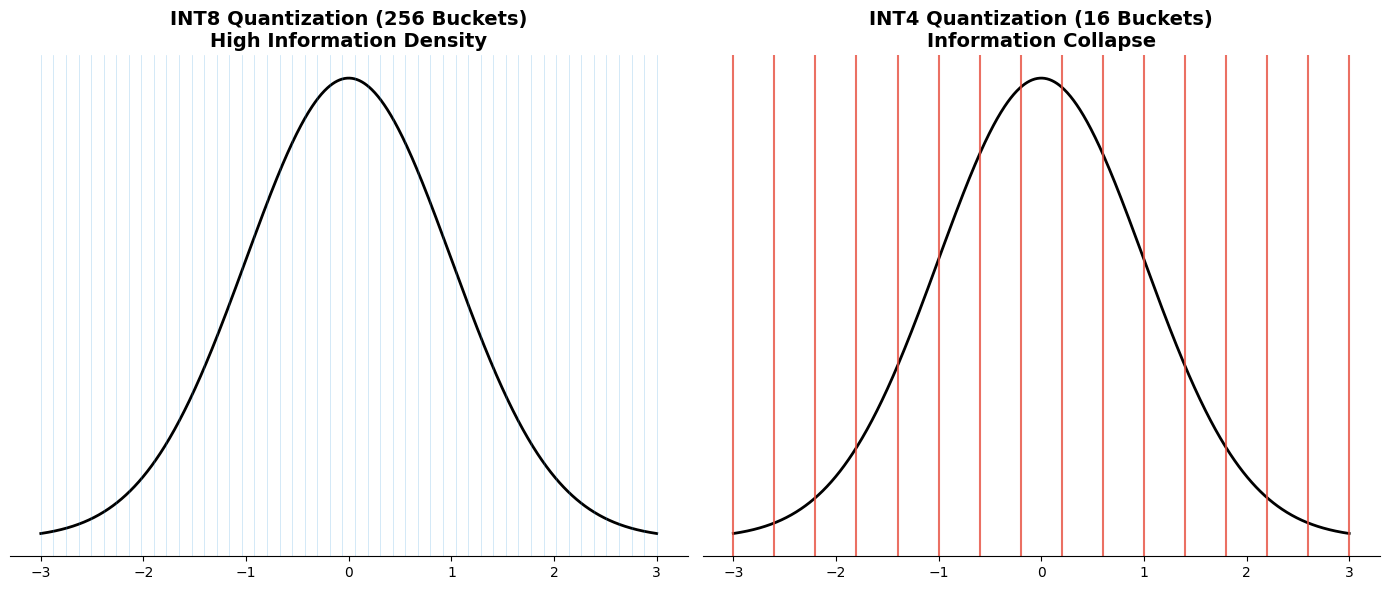
Standard quantization methods simply try to round every weight to the nearest bucket. At 4 bits, this rounding error is catastrophic.
Step 3: The Paradigm Shift - Output Error vs. Weight Error
To solve this, we need a complete shift in perspective.
Traditionally, quantization focuses on minimizing Weight Error: trying to make the compressed weight look as mathematically close to the original weight as possible.
Advanced methods like QUIP and QTIP focus on minimizing Output Error: trying to make the behavior of the model remain the same, regardless of the individual weight changes.
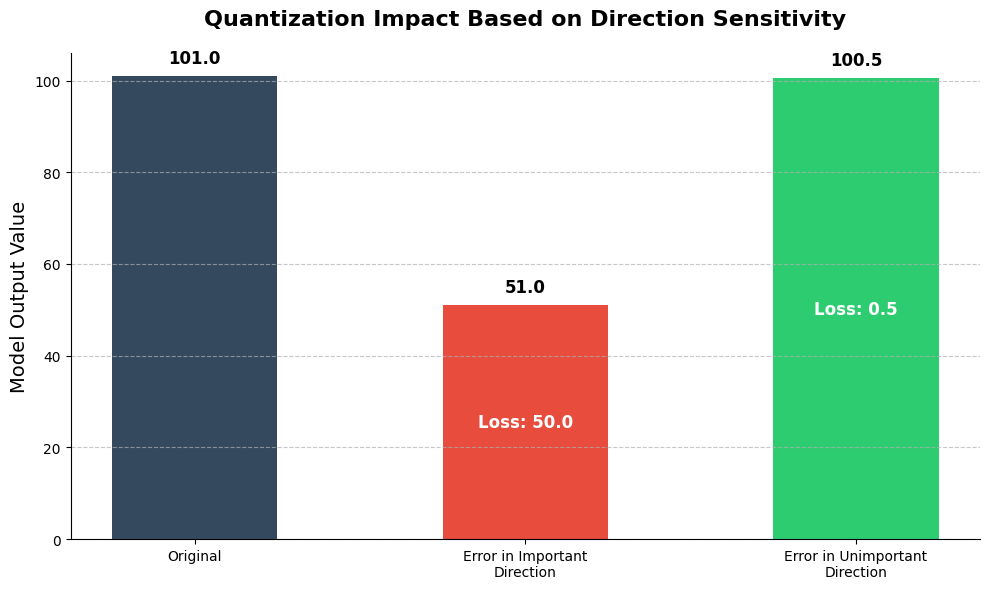
If changing a weight doesn’t change the final output of the network much, then we don’t care if that weight has a huge error!
Step 4: Sensitive Directions & Error Shaping
This brings us to the core innovation of QUIP: Error Shaping.
Not all directions in a neural network are equally important. Some directions (activations) are highly sensitive, where even tiny errors will cause the model to hallucinate or break. Other directions are completely insensitive.
Instead of uniform quantization, QUIP intentionally pushes (or “shapes”) the quantization error away from the sensitive directions and dumps it into the insensitive directions.
Step 5: The Power of Rotation
How do we actually separate the important and unimportant directions? They are usually mixed together inside a weight matrix.
The answer is Mathematical Rotation.
By applying an orthogonal rotation to the weights and activations before quantization, QUIP aligns the information. After rotation, quantization error naturally lands more often in the directions that matter less.
The same amount of absolute quantization error can either destroy model quality or barely matter, depending purely on which direction it affects. Rotation guarantees we protect the important ones.
Step 6: Vector Quantization
While normal quantization compresses individual numbers (scalars), QUIP moves to Vector Quantization.
Instead of storing every weight, we store a small set of representative vectors called Prototypes. Then, for the millions of weights in the model, we only need to store a tiny index pointing to the closest Prototype.
Store A Small Set Of Representative Vectors
+
Store Tiny Indexes
This delivers incredible compression, but it introduces a major problem during inference: the GPU hates random memory lookups. Constantly looking up Prototypes from an index kills the speed.
Step 7: Bringing It All Together With QTIP
QTIP (Quantization with Trellises and Incoherent Processing) asks the final question: How do we get the compression benefits of QUIP without slowing inference to a crawl?
Instead of an arbitrary table of Prototypes that the GPU has to fetch from memory, QTIP introduces Codewords.
A codeword is a highly structured identifier that represents a vector. Because it follows strict mathematical rules, the GPU can reconstruct the vector on-the-fly instantly, avoiding slow memory lookups.
Codeword ID → Tiny Mathematical Rule → Vector
QTIP stores representative vectors in a form that GPUs can reconstruct and multiply extremely efficiently. This is the magic that allows sub-8-bit quantization with minimal quality degradation and blazing fast inference speeds.
Comment down your thoughts below, if you found it helpful!
References
QuIP: 2-Bit Quantization of Large Language Models With Guarantees QTIP: Quantization with Trellises and Incoherent ProcessingBest,
Ankit