Understanding Self-Attention: From First Principles
Sun Jun 07 2026
Self-Attention from First Principles. I have read a lot of articles and watched many videos, and I noticed that no one explains this incredibly important topic in the easiest manner.
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Most resources require you to be highly proficient in Deep Learning and its advanced mathematics to fully grasp the concepts.
But Self-Attention is actually simple if learned the right way.
At its core, Self-Attention relies on just three foundational components:
- Dot Product (The Matching Tool)
- Weights (The Learnable Transformation)
- Data (The Values to Transmit)
Self-attention was the core innovation that enabled the Transformer architecture, which ultimately transformed modern AI, that we see today.
I won't start with abstract formulas, instead,
I will break things down in the simplest way possible by giving you raw intuition first, building up to the complete mathematical matrix.
Let's begin.
Step 1: We Have a Sentence
"My name is Ankit"
The Tokenizer converts these words into numerical IDs:
[523, 1024, 98, 4567]
These numbers are just IDs with no inherent meaning yet. Think of them as simple mappings:
My = 523
name = 1024
is = 98
Ankit = 4567
They are just labels, exactly like a Student ID or an Employee ID.
Step 2: Embedding Layer
Now we need to add meaning. Suppose our embedding dimension is 2 for learning purposes. The model uses a large lookup table called an embedding table:
| Token ID | Embedding Vector |
|---|---|
| 523 | $[0.12, \phantom{-}0.33]$ |
| 1024 | $[0.51, -0.20]$ |
| 98 | $[0.22, \phantom{-}0.78]$ |
| 4567 | $[0.88, \phantom{-}0.12]$ |
Mapping our tokens to vectors gives us this structured representation:
| Word | Dimension 1 | Dimension 2 | Vector Representation ($\vec{x}$) |
|---|---|---|---|
| My | 0.12 | 0.33 | [0.12, 0.33] |
| name | 0.51 | -0.20 | [0.51, -0.20] |
| is | 0.22 | 0.78 | [0.22, 0.78] |
| Ankit | 0.88 | 0.12 | [0.88, 0.12] |
Question: What does a vector like [0.12, 0.33] actually mean?
Answer: Nobody knows exactly. This is a very important concept to understand.
People often assume:
0.12= person score0.33= noun score
This is not true. The vector represents a compressed meaning.
Step 3: Put All Embeddings Together
Next, we stack these individual vectors together into a single data matrix, which we call $X$. Let's break down the assembly of this matrix line by line, mapping each word to its specific row.
First, we take the vector for My:
X =
[
[0.12, 0.33]
]
Next, we stack the vector for name directly underneath:
X =
[
[0.12, 0.33],
[0.51, -0.20]
]
Then, we append the vector for is:
X =
[
[0.12, 0.33],
[0.51, -0.20],
[0.22, 0.78]
]
Finally, we add the vector for Ankit to complete our sequence:
X =
[
[0.12, 0.33],
[0.51, -0.20],
[0.22, 0.78],
[0.88, 0.12]
]
To visualize this explicitly, we can view the finished matrix with its corresponding word rows:
X =
[
[My],
[name],
[is],
[Ankit]
]
=
[
[0.12, 0.33],
[0.51, -0.20],
[0.22, 0.78],
[0.88, 0.12]
]
Shape of X
- Rows = 4: Because we have 4 tokens (My, name, is, Ankit).
- Columns = 2: Because our embedding dimension is 2.
Therefore, the shape of our matrix is:
$$X \in \mathbb{R}^{4 \times 2}$$
Visualization
Think of each word as a point in an embedding space.
The coordinates of the point are the values inside the embedding vector.
For example:
My → [0.12, 0.33] name → [0.51, -0.20] is → [0.22, 0.78] Ankit → [0.88, 0.12]
In this toy 2D example, each embedding can be visualized as a point on a graph.
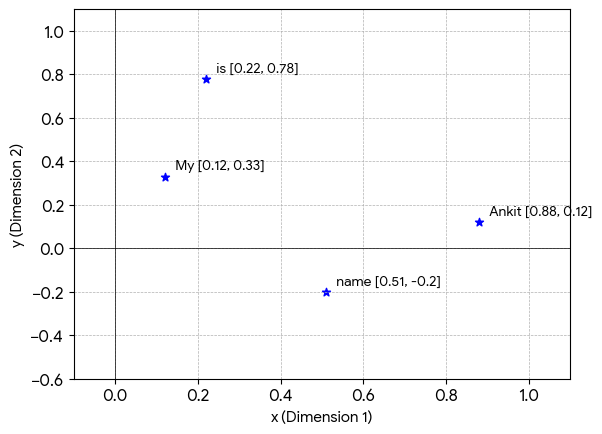
An Important Realization
At this stage:
- My does NOT know that name exists.
- Ankit does NOT know that My exists.
Each token is completely independent. We only have Word Meaning, not Sentence Meaning yet.
What Problem Does Attention Solve?
Currently, we know:
Ankit = [0.88, 0.12]
But the vector for Ankit has no idea it is appearing inside the specific sentence "My name is Ankit".
The model needs Ankit to learn that it is contextualized by and related to My, name, and is.
This is the exact motivation for Self-Attention.
Before Q, K, V: Raw Intuition
Let's ask a fundamental question:
If I am the word "Ankit", how can I determine which other words in this sentence are important to me?
A simple, intuitive approach is to compare my embedding with every other embedding using a mathematical operation called the dot product:
- Ankit $\leftrightarrow$ My
- Ankit $\leftrightarrow$ name
- Ankit $\leftrightarrow$ is
This gives us our very first attention intuition: measuring similarity between words.
The Math: Computing Dot Products Manually
Let's compute the similarity scores for the word Ankit on paper.
Our Embeddings Reference
- My:
[0.12, 0.33] - name:
[0.51, -0.20] - is:
[0.22, 0.78] - Ankit:
[0.88, 0.12]
What is a Dot Product?
For two vectors $\vec{a} = [a_1, a_2]$ and $\vec{b} = [b_1, b_2]$, the dot product is calculated by multiplying corresponding elements and summing them up:
$$\vec{a} \cdot \vec{b} = a_1b_1 + a_2b_2$$
Dot Product 1: Ankit $\cdot$ My
$$[0.88, 0.12] \cdot [0.12, 0.33]$$
- Step 1: $0.88 \times 0.12 = 0.1056$
- Step 2: $0.12 \times 0.33 = 0.0396$
- Step 3: $0.1056 + 0.0396 = 0.1452$
$$\text{Ankit} \cdot \text{My} = 0.1452$$
Dot Product 2: Ankit $\cdot$ name
$$[0.88, 0.12] \cdot [0.51, -0.20]$$
- Step 1: $0.88 \times 0.51 = 0.4488$
- Step 2: $0.12 \times (-0.20) = -0.0240$
- Step 3: $0.4488 - 0.0240 = 0.4248$
$$\text{Ankit} \cdot \text{name} = 0.4248$$
Dot Product 3: Ankit $\cdot$ is
$$[0.88, 0.12] \cdot [0.22, 0.78]$$
- Step 1: $0.88 \times 0.22 = 0.1936$
- Step 2: $0.12 \times 0.78 = 0.0936$
- Step 3: $0.1936 + 0.0936 = 0.2872$
$$\text{Ankit} \cdot \text{is} = 0.2872$$
Dot Product 4: Ankit $\cdot$ Ankit
$$[0.88, 0.12] \cdot [0.88, 0.12]$$
- Step 1: $0.88 \times 0.88 = 0.7744$
- Step 2: $0.12 \times 0.12 = 0.0144$
- Step 3: $0.7744 + 0.0144 = 0.7888$
$$\text{Ankit} \cdot \text{Ankit} = 0.7888$$
Final Similarity Scores For "Ankit"
| Compared With | Dot Product Score |
|---|---|
| Ankit | 0.7888 |
| name | 0.4248 |
| is | 0.2872 |
| My | 0.1452 |
In this toy embedding space, Ankit is mathematically closest to itself, followed by name, is, and lastly My.
Why Does the Dot Product Measure Similarity?
- Aligned Vectors: If two vectors point in a highly similar direction, their dot product yields a large positive value.
- Opposite Vectors: If two vectors point in completely opposite directions, their dot product yields a negative value.
- Orthogonal Vectors: If two vectors point at a $90^\circ$ angle to each other, their dot product is exactly $0$ (completely unrelated).
- Large Positive Score $\rightarrow$ Similar direction
- Near Zero Score $\rightarrow$ Unrelated
- Negative Score $\rightarrow$ Opposite direction
The Problem With the Current Equation
If we calculate attention scores directly using our raw input embeddings, we are effectively doing a pure matrix multiplication:
$$\text{Score} = XX^T$$
This leads to three fundamental problems:
Problem 1: No Learnable Parameters
This is just a mathematical operation. With no learnable parameters, we can't train it.
Take the sentence: "I love Apple Watch"
The model might not be able to understand that Apple Watch is a single entity. It may interpret Apple as a fruit and Watch as a clock or the verb see.
Problem 2: Fixed Geometry
Because attention simply asks: "Which vectors are already close to me in this fixed space?", there is no learning, no adjustment, and no control.
The embedding space is created before attention (via word2vec, GloVe, or an embedding layer). This space already has its own bias:
Appleis close toFruitAppleis somewhat close toPhone- But the
Fruitsimilarity is often stronger globally.
Problem 3: Symmetrical Similarity
In a simple dot product, the similarity between Apple and Phone is the exact same as Phone and Apple.
They will both be pulled together, shifting the overall distribution. We may want Apple to shift towards Phone, but we don't necessarily want Phone to shift towards Apple.
The "Apple Watch" Problem: Visualized
Let's say our embedding space looks like this:
Apple ──── Fruit (very close)
│
│
│
Phone (farther away)
Now, self-attention computes similarity. The result? Apple attends more to Fruit meaning, even though Fruit is not in the sentence. The relation to Phone is weaker geometrically.
Why does this confusion happen? Because attention says: "I trust the existing embedding geometry." But that geometry was trained on the entire internet, not this specific sentence.
So:
- It cannot reinterpret
Apple. - It cannot shift meaning.
- It cannot prefer
PhoneoverFruit.
Without learnable parameters, attention cannot change meaning — it can only reveal existing similarity.
How Learnable Parameters Fix This
Learnable parameters change the geometry. Without them, geometry is fixed.
What $W_Q$, $W_K$, $W_V$ Really Are
They are learned transformations that say: "For Attention, this is what matters. Ignore the rest."
Learnable parameters DO NOT add knowledge. They reshape space.
In a Transformer attention layer, the main learnable parameters are weight matrices:
- $W_Q$ = Weights for Queries (How to ask)
- $W_K$ = Weights for Keys (How to match)
- $W_V$ = Weights for Values (What meaning to pass)
- $W_O$ = Weights after attention (Output projection)
Each of these is just a matrix of numbers. For understanding attention geometry, weights matter much more than biases.
Each weight matrix mathematically:
- Rotates space
- Stretches space
- Compresses space
Revisiting the Sentence With Learnable Parameters
Sentence: "I love Apple Phone"
What training teaches the model:
From millions of examples, it learns that when words like phone, iphone, android, or love appear, Apple should move toward their meaning.
So during attention, a geometric change happens.
Original Space:
Apple ──── Fruit (closer)
│
│
Phone
After Learning Projection:
Apple ──── Phone (closer)
\
\
Fruit (pushed away)
This is the entire difference.
Without learnable parameters, self-attention can only measure similarity. With learnable parameters, self-attention can create similarity.
Learnable parameters don't change geometry per sentence. They learn how geometry should change WHEN CERTAIN CONTEXTS APPEAR.
Intuition Towards Self-Attention
If the model predicts poorly on "I love apple phone", that means Apple did not attend strongly enough to Phone, as it is strongly similar to Fruit.
So during backpropagation, weight updating happens.
Learning says:
- Increase alignment between
Apple(Query) andPhone(Key). - Decrease alignment with irrelevant words.
How? By slightly changing the numbers inside $W_Q$ and $W_K$.
The Mathematical Intuition
The model makes a wrong guess $\rightarrow$ sees the error $\rightarrow$ slightly adjusts the geometry. Next time, similar sentences work better. That's all learning is.
Let's unpack this slowly:
Step 1: What the model is trying to learn
Input: "I love apple phone"
The model's job is to understand Apple as a brand, not as a fruit.
At the beginning (with random weights), the geometry is bad. Attention connects Apple weakly to Phone and strongly to Fruit.
Step 2: What "Wrong" Means
During training, the model is usually asked to predict the next word or fill a masked word:
- Input:
I love apple: _______ - Target:
phone
If the model fails to predict phone, that means attention did not focus enough on the right relationship. It may have considered Apple as Fruit.
Step 3: Adjust Weights
Now we adjust our 3 matrices: $W_Q$, $W_K$, and $W_V$.
Step 4: Geometry Adjustment
The system thinks: "When apple appears with phone, I should make them look more similar."
What does it do? It rotates the Query direction of Apple and rotates the Key direction of Phone.
So next time, their dot product is bigger, and their attention weight increases.
Under the hood, the system knows:
- "Output was wrong."
- "Which parameters influenced that output."
So it nudges them: "Increase this similarity a bit, decrease that similarity a bit." This is gradient descent—trial $\rightarrow$ feedback $\rightarrow$ correction.
Why This Works Over Time
One sentence teaches very little. But after 10 million sentences, the model slowly learns:
- In tech contexts $\rightarrow$
Applealigns withPhone,Laptop. - In food contexts $\rightarrow$
Applealigns withFruit.
The model never learns "Apple = Phone". It learns "WHEN Apple should look like Phone".
The Self-Attention Formula
Now that we understand the intuition behind learnable parameters, let's look at the actual mathematical formula that ties everything together:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Where our queries, keys, and values are generated by multiplying our input $X$ with our learned weight matrices: $$Q = X \cdot W_Q \quad \text{(Queries)}$$ $$K = X \cdot W_K \quad \text{(Keys)}$$ $$V = X \cdot W_V \quad \text{(Values)}$$
Let's break down exactly what each piece of this formula is doing:
- $QK^T$ (The Matching Engine): This is the row-by-row dot product multiplication. It is where every Query asks every Key: "How relevant are you to me?"
- $\sqrt{d_k}$ (The Scaler): This is a safety buffer. $d_k$ is the dimension size of our keys. If our dimensions get too large, the dot product scores blast through the roof, which breaks the math during training. Dividing by $\sqrt{d_k}$ keeps the numbers stable.
- $\text{softmax}(\dots)$ (The Normalizer): This is the activation function that turns our raw matching scores into probabilities (ranging from 0 to 1).
- $V$ (The Information Carrier): Finally, we multiply those percentages by the actual data payload matrix ($V$) to extract the exact contextual meaning we need.
Now, let's look at the raw matrix mechanics of just that first crucial step: the matching engine, $QK^T$.
The Math of $QK^T$: Step-by-Step Matrix Mechanics
Let's watch the magic happen mathematically. Let's look exclusively at the matrix multiplication $Q K^T$. We will forget Softmax and $V$ for a brief moment just to master how queries match keys.
Assume our text matrix has been projected into $Q$ and $K$ spaces (using 2-dimensional representations for simplicity):
Q (Query Matrix)
[
[1, 0], // My Query
[0, 1], // name Query
[1, 1], // is Query
[2, 1] // Ankit Query
]
K (Key Matrix)
[
[1, 1], // My Key
[0, 2], // name Key
[1, 0], // is Key
[2, 1] // Ankit Key
]
Both matrices have a shape of $(4, 2)$ because we have $4 \text{ tokens} \times 2 \text{ dimensions}$.
To perform a dot product of every row in $Q$ with every row in $K$, we transpose $K$ so it has a shape of $(2, 4)$:
Kᵀ (Key Matrix Transposed)
[
[1, 0, 1, 2],
[1, 2, 0, 1]
]
Now we compute the matrix multiplication: $Q_{(4 \times 2)} \times K^T_{(2 \times 4)} = \text{Score}_{(4 \times 4)}$. Why $4 \times 4$? Because every single token compares itself with every single token!
Computing Row 1: The "My" Token Perspective
We take the Query vector for My ($[1,0]$) and cross-multiply it with all word Keys in $K^T$:
- My Query $\cdot$ My Key: $[1,0] \cdot [1,1] = 1(1) + 0(1) = \mathbf{1}$
- My Query $\cdot$ name Key: $[1,0] \cdot [0,2] = 1(0) + 0(2) = \mathbf{0}$
- My Query $\cdot$ is Key: $[1,0] \cdot [1,0] = 1(1) + 0(0) = \mathbf{1}$
- My Query $\cdot$ Ankit Key: $[1,0] \cdot [2,1] = 1(2) + 0(1) = \mathbf{2}$
Row 1 results in: [1, 0, 1, 2]
Computing Row 4: The "Ankit" Token Perspective
We take the Query vector for Ankit ($[2,1]$) and cross-multiply it with all word Keys in $K^T$:
- Ankit Query $\cdot$ My Key: $[2,1] \cdot [1,1] = 2(1) + 1(1) = \mathbf{3}$
- Ankit Query $\cdot$ name Key: $[2,1] \cdot [0,2] = 2(0) + 1(2) = \mathbf{2}$
- Ankit Query $\cdot$ is Key: $[2,1] \cdot [1,0] = 2(1) + 1(0) = \mathbf{2}$
- Ankit Query $\cdot$ Ankit Key: $[2,1] \cdot [2,1] = 2(2) + 1(1) = \mathbf{5}$
Row 4 results in: [3, 2, 2, 5]
The Complete $QK^T$ Score Matrix
Filling out the entire matrix gives us an actionable relationship grid:
QKᵀ (Attention Score Matrix)
[
[ My (K), name (K), is (K), Ankit (K) ],
[ My (Q), 1, 0, 1, 2 ],
[ name (Q), ., ., ., . ],
[ is (Q), ., ., ., . ],
[ Ankit (Q), 3, 2, 2, 5 ]
]
💡 The Deep Reading Intuition: Always read this matrix row by row. The row belongs to the Query (the word asking the question), and the columns belong to the Keys (the tokens responding). Looking at the Ankit row, its scores are
[3, 2, 2, 5]. This means that while processing the word Ankit, the model determines it is highly self-relevant ($5$), but its strongest structural connection out of the remaining tokens is to the word My ($3$).
What Happens Next: Softmax and the Value Matrix ($V$)
Once we have our score matrix, we finish the rest of the standard attention pipeline:
1. Scaling and Softmax
We turn these raw score matrices into percentages. For example, applying Softmax to the Ankit row [3, 2, 2, 5] converts those numbers into normalized probabilities that equal $100%$:
Ankit Attention Weights: [ My: 12%, name: 5%, is: 5%, Ankit: 78% ]
2. Gathering the Values ($V$)
Now that we know exactly how much attention to pay to each word, we multiply these percentage weights by the Value Matrix ($V$).
Instead of passing the original data or keys forward, we pull information directly from $V$. If a token has an attention score of $78%$ on itself and $12%$ on My, its final output vector will be a blended compound containing $78%$ of its own value profile and $12%$ of My's value profile.
Comment down your thoughts below, if you found it helpful !
References
Attention Is All You NeedBest,
Ankit